Recap
In the previous blog post, we explored how a lexer (or lexical analyzer) transforms raw source code into a stream of tokens. This token stream forms the backbone of the compiler’s input for further processing. However, this flat sequence of categorized words and symbols doesn’t yet reveal the actual structure or meaning of the code.
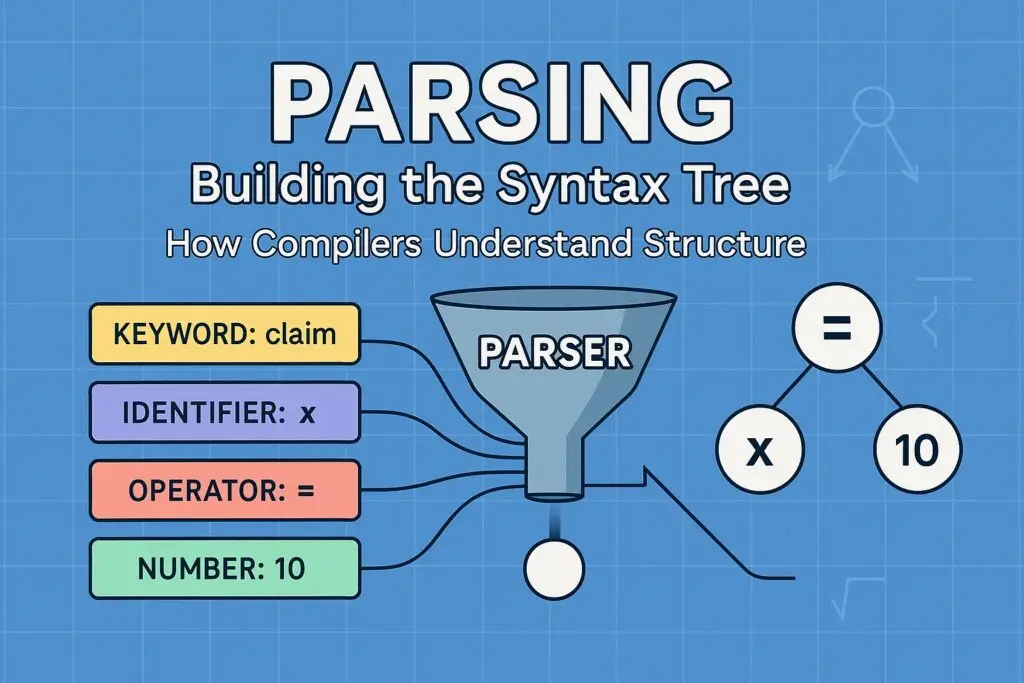
For example, from the lexer we may receive something like:
[KEYWORD: claim] [IDENTIFIER: x] [OPERATOR: =] [NUMBER: 10] [DELIMITER: ;]
But how do we know what this really means? Is it a variable declaration? An assignment? A statement?
This is where the parser steps in — the second stage of compilation. Let’s explore how this crucial component transforms a stream of tokens into a structured representation of code.
What Is a Parser? Parser Definition
A parser (or syntax analyzer) is a program that takes the token stream produced by a lexer and turns it into a structured representation—most commonly an Abstract Syntax Tree (AST).
The Parser’s Job:
- It validates that the code follows the grammar of the language.
- It captures hierarchical structure (like nesting and operator precedence).
- It identifies meaningful syntactic constructs like expressions, statements, functions, loops, etc.
Let’s think of the compiler like a language teacher:
- The lexer highlights parts of speech (noun, verb, adjective).
- The parser turns those parts into grammatically correct sentences.
In technical terms, the parser consumes terminals (tokens) and builds non-terminals (higher-level constructs like expressions or statements), all while adhering to rules defined by the language’s context-free grammar (CFG).
Why Do We Need a Parser?
You might ask, “If we already have tokens, why not work with them directly?”
Here’s why the parser is essential:
1. Structure and Hierarchy
A program is not just a linear stream of tokens. There are nested expressions, conditionals, loops, etc. The parser builds this hierarchy so that the compiler can understand what goes where.
2. Grammar Enforcement
Parsers ensure code follows language rules:
- Does the if statement have a condition?
- Is every create function followed by parameters and a block?
- Are parentheses balanced?
3. Bridge to Semantics
Once the syntax is validated, we can move to semantic checks like:
- Is this variable declared?
- Are the types compatible?
- Is the function being called correctly?
4. Tooling Support
Parsers power features like:
- Syntax highlighting
- Autocompletion
- Real-time syntax error detection in IDEs
Types of Parsers
Top-Down Parsers
These parse from the top-level rules downward, starting from the start symbol.
Recursive Descent Parser
- Manual implementation
- One function per non-terminal
- Easy to write and debug
- Can’t handle left-recursive grammars
Example:
int parseExpr() {
if (lookahead == NUMBER) return match(NUMBER);
if (lookahead == LPAREN) {
match(LPAREN);
parseExpr();
match(RPAREN);
}
}
Bottom-Up Parsers
These work by reducing tokens into non-terminals, working from the leaves (tokens) up to the root of the grammar tree.
Shift-Reduce Parsing
- Used by parser generators like Bison, Yacc
- Supports left recursion, complex rules
- Requires grammar to be defined in a .y file
- Produces fast and efficient parsers
Context-Free Grammars (CFGs)
A CFG is a set of production rules that describe how tokens can be combined into valid language constructs.
Example Grammar (for arithmetic expressions):
Expr -> Expr + Term | Term
Term -> Term * Factor | Factor
Factor -> ( Expr ) | number
This tells us:
- An expression can be two terms added together.
- A term can be two factors multiplied.
- A factor is either a number or a nested expression.
Terminology:
- Terminals: Actual tokens (e.g., +, *, number, (, )).
- Non-terminals: Grammar symbols like Expr, Term, Factor.
- Production rule: How a non-terminal can be formed.
Parser Construction
There are two common approaches to building a parser:
Option 1: Manual Parser (Recursive Descent)
Best for simple grammars. Requires you to write functions for each rule.
Pros:
- Full control
- Great for learning
Cons:
- Tedious for complex languages
- Doesn’t handle ambiguity well
Option 2: Using Bison (Shift-Reduce Parser)
Bison is a tool that generates a parser from a .y grammar file.
How It Works:
- Tokens come from the lexer.
- Bison matches them against the rules.
- When a rule matches, it reduces the symbols and performs an action (e.g., build an AST node).
Using Bison: Turning Grammar into a Parser
As your language grows in complexity — from simple expressions to nested conditionals, function calls, and user-defined types — writing your own recursive descent parser becomes cumbersome. That’s when Bison, a powerful parser generator, shines.
Bison takes in a high-level description of your language grammar and generates C/C++ code to parse that grammar, complete with conflict resolution, state management, and error handling.
Creating a .y Grammar File
The heart of a Bison-based parser is the .y file (often named something like parser.y or flare.y). This file is divided into three sections, separated by %%:
yacc
%{
// C/C++ header includes and declarations go here
#include <iostream>
using namespace std;
%}
%token NUMBER IDENTIFIER PLUS MINUS MULTIPLY DIVIDE
%%
expr: expr PLUS term
| expr MINUS term
| term
;
term: term MULTIPLY factor
| term DIVIDE factor
| factor
;
factor: NUMBER
| IDENTIFIER
| '(' expr ')'
;
%%
Let’s break this down.
1. Defining Terminal Tokens (Lexical Tokens)
All the tokens that the lexer returns must be declared using the %token directive. These include:
- Literals: PLUS, MINUS, MULTIPLY, DIVIDE
- Identifiers: like variable names
- Literals: like NUMBER, STRING, etc.
These names must match what your lexer (e.g., yylex) returns. If your lexer returns PLUS, then %token PLUS must be declared.
You can even assign literal values using ‘%token’ like this:
yacc
%token <int> NUMBER
%token '+' '-' '*' '/'
…but using symbolic names is clearer and better for extensibility.
2. Defining Non-Terminal Symbols
Non-terminals like expr, term, factor, etc., are defined implicitly in the grammar rules section. These represent composite language structures.
Each non-terminal corresponds to a rule or a combination of rules — and that’s how your language syntax is shaped.
3. Writing Grammar Rules
Grammar rules are written in the format:
non_terminal: expansion1
| expansion2
;
Each expansion is made of tokens and/or other non-terminals, defining how a valid sequence of tokens can form that structure.
Example:
expr: expr PLUS term
| term;
This means expr can be either another expr followed by a PLUS and a term, or just a term.
Note: In this phase, we’re not embedding C++ actions (e.g., { $$ = new AddNode(…); }). We’ll add semantic actions when building the AST in the next part.
Common Pitfalls to Watch Out For
Many beginners face issues when using Bison for the first time. Here are some common ones and how to avoid them:
Left Recursion vs Right Recursion
- Left recursion (like expr: expr ‘+’ term) is supported and preferred in Bison because it builds left-associative parsers.
- Right recursion leads to deeper stack usage.
Stick to left recursion unless you have a good reason otherwise.
Unresolved Tokens
If Bison complains about an “undeclared token,” check that your %token declarations match exactly with what your lexer returns.
Shift/Reduce and Reduce/Reduce Conflicts
If you see these warnings:
1 shift/reduce conflictDon’t panic — Bison resolved it automatically, usually preferring shift. But:
- Re-express your grammar to eliminate ambiguity.
- Use precedence and associativity declarations if needed:
%left '+' '-'
%left '*' '/'
These resolve ambiguities like a + b * c correctly as a + (b * c).
Naming Consistency
Make sure your yylex() function returns the same token names declared in %token.
Compiling the Grammar with Bison
Once your .y file is written, compile it using:
bison -d flare.yThis will generate two files:
- flare.tab.cpp — the actual parser code
- flare.tab.hpp — header file with token definitions and parser declarations
The -d flag tells Bison to generate the .hpp file, which is important for interfacing with the lexer and other components.
Integration into the Compiler Pipeline
Here’s how this fits into your compiler:
- Lexer scans raw code and returns tokens via yylex().
- Parser (using flare.tab.cpp) receives the token stream and verifies syntax.
- In this stage, it only checks grammar rules — no AST is built yet.
- Later, we’ll modify this to construct the AST directly in the .y file using semantic actions.
Typical call in main.cpp:
extern int yyparse();
yyparse();
And link everything together:
g++ -o flare main.cpp flare.tab.cpp lexer.cppBy using Bison, you offload the hard work of managing parser states, precedence, and syntax trees, freeing yourself to focus on semantics and code generation. In the next part, we’ll extend the .y file to build an AST directly as parsing happens.
Let’s build smart — not from scratch.
Parsing a Simple Expression Language
Input Code:
3 + 4 * (2 – 1)
Token Stream:
[NUMBER: 3] [OP: +] [NUMBER: 4] [OP: *] [LPAREN] [NUMBER: 2] [OP: -] [NUMBER: 1] [RPAREN]
AST Built by Parser:
+
/ \
3 *
/ \
4 -
/ \
2 1
The parser’s job is to make sure the order of operations (precedence and associativity) is respected. In this case, * and – bind tighter than +. We will see in next post that how we can modify grammar to get the AST nodes in C++.
Integration With Compiler Pipeline
Once parsing is complete, we have a structured tree (AST) that represents the source code.
From here:
- Semantic Analysis: Check types, declarations, scope.
- Code Generation: Translate the AST into machine code, bytecode, or LLVM IR.
Simplified Pipeline:
Source Code
↓
Lexer → Tokens
↓
Parser → AST
↓
Semantic Analyzer
↓
Code Generator
Summary
- A parser transforms flat token streams into structured syntax trees.
- It uses context-free grammar to guide this transformation.
- Parsers can be written by hand (top-down) or generated using tools like Bison (bottom-up).
- Parsing enables semantic analysis and code generation by exposing hierarchical structure.
Understanding parsing gives you the ability to define how your language works—and that’s the heart of compiler design.
Next Steps
In the next post, we’ll look at how we can create the AST to perform:
- Variable and function resolution
- Type checking
- Scope management
This will lay the foundation for generating optimized and type-safe code.