Learn what an Abstract Syntax Tree (AST) is, how it works in compiler design, and how to build an AST in C++ using Bison. This Abstract Syntax Tree tutorial breaks down AST creation for the compiler design.
Recap
Welcome back! In the previous post, we explored how parsers work, how to define grammars using Bison, and how they transform a stream of tokens into structured syntactic forms. But our parser currently just verifies whether the input code “fits” the grammar — it doesn’t produce anything useful for actual compilation.
Now it’s time to build the real heart of our compiler: the Abstract Syntax Tree, or AST.
What Is an AST?
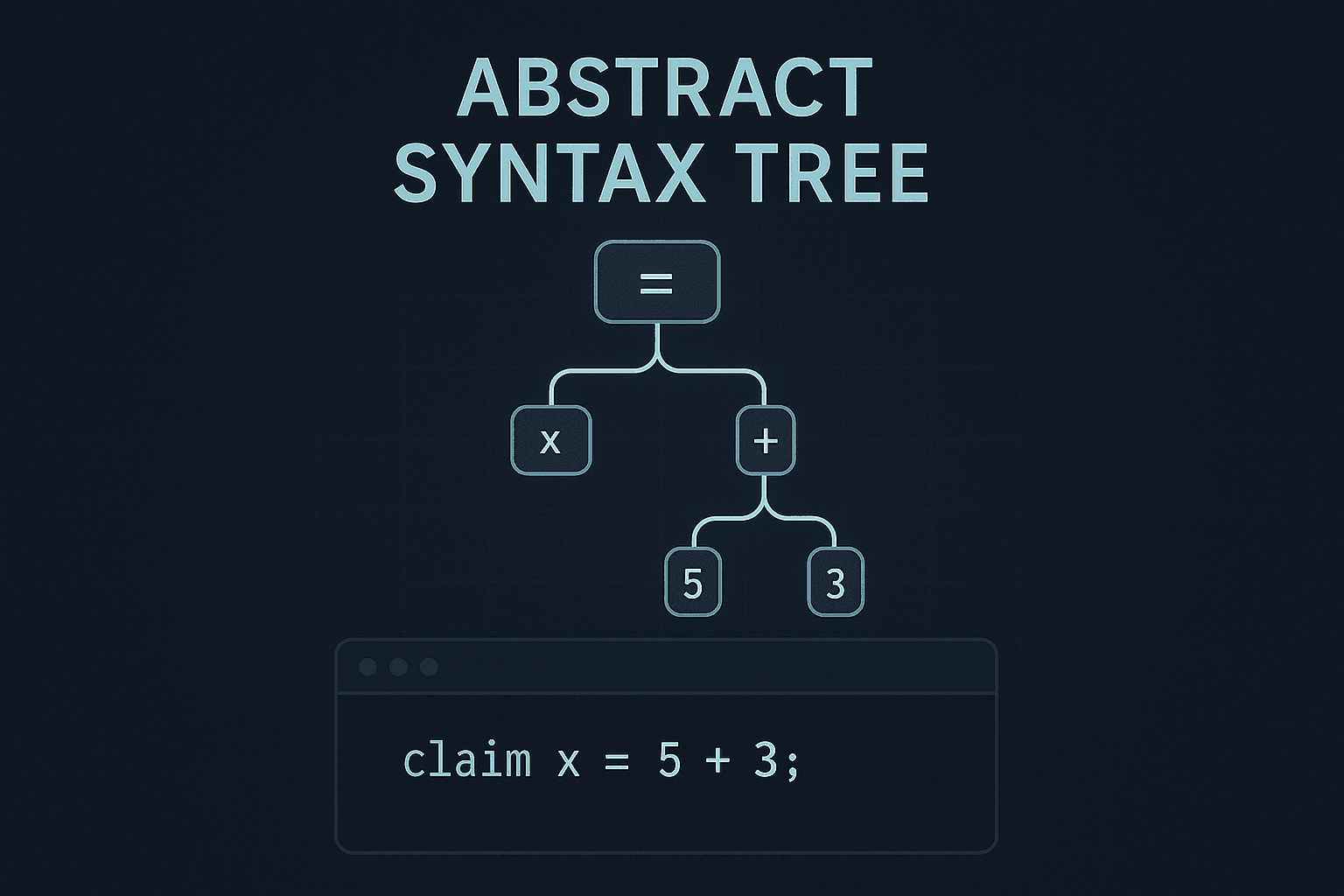
An Abstract Syntax Tree is a tree representation of the semantic structure of source code. While a parser checks whether the code is syntactically correct, the AST captures the actual meaning behind that syntax — in a clean, structured format.
Think of it like this:
If source code is a paragraph, and the parse tree is the full grammatical analysis, then the AST is the key ideas in a bullet list. It ignores fluff like commas and parentheses and just tells you what is being done.
Example: a + b * c
This tiny expression goes through multiple stages:
Tokens:
IDENTIFIER(a), PLUS(+), IDENTIFIER(b), STAR(*), IDENTIFIER(c)Parse Tree (concrete syntax tree):
Expr
├── Expr
│ └── IDENTIFIER(a)
├── PLUS
└── Expr
├── IDENTIFIER(b)
├── STAR
└── IDENTIFIER(c)
AST:
(+)
/ \
a (*)
/ \
b c
Notice how parentheses, precedence, and operator associativity are already resolved in the AST. It shows what operations occur and in what order — not how they were written.
AST vs Parse Tree: What’s the Difference?
Feature | Parse Tree (CST) | Abstract Syntax Tree (AST) |
Keeps all syntax details | Yes | No (only essential info) |
Includes parentheses, commas | Yes (All Terminal Tokens) | No |
Focuses on meaning | More about form | Semantic intent |
Tree depth | Deeper due to grammar rules | Shallower, more concise |
Used for code generation | Rarely | Always |
In essence, the AST strips away everything we don’t need and keeps just enough to understand and generate working machine code.
Where AST Fits in the Compiler Pipeline
Let’s zoom out and see where AST fits:
Source Code
↓
Lexer → Tokens
↓
Parser → Parse Tree
↓
-> AST (used for all future phases!)
↓
Semantic Analyzer
↓
Code Generator (LLVM IR)
↓
Executable
Without an AST, writing optimizations, performing type checks, or generating efficient code becomes near-impossible.
Designing AST Nodes
AST is Built from “Nodes”
Every programming construct (expression, variable, function, loop, etc.) maps to a different type of node in the AST.
Core Idea:
We define a base ASTNode class and then build specific node types on top of it, such as BinaryExprNode, NumberNode, FuncDeclNode, etc.
Example in C++:
// Base class for all AST nodes
class ASTNode {
public:
virtual ~ASTNode() = default;
virtual void print() = 0; // For debugging
};
Binary Expression Node (e.g., a + b)
class BinaryExprNode : public ASTNode {
public:
string op;
shared_ptr<ASTNode> left;
shared_ptr<ASTNode> right;
BinaryExprNode(const string& oper, shared_ptr<ASTNode> l, shared_ptr<ASTNode> r)
: op(oper), left(l), right(r) {}
void print() override {
cout << "(" << op << " ";
left->print();
cout << " ";
right->print();
cout << ")";
}
};
Literal Node
class IntLiteralNode : public ASTNode {
public:
int value;
IntLiteralNode(int v) : value(v) {}
void print() override {
cout << value;
}
};
You’ll build a tree of these objects, where each node represents part of the code’s meaning.
Connecting AST with Bison Grammar (Step-by-Step AST Construction)
Now that we’ve built the structure for our AST using C++ classes, the next step is to generate that AST while parsing, using our Bison grammar file (typically named flare.y).
In this section, we’ll walk you through how to modify your .y file so that every rule in your grammar produces an AST node, and how those nodes get connected to form a complete tree representing the entire program.
This is where the parser becomes not just a checker of syntax, but a builder of meaning.
Step 1: Include AST Classes in Your Bison File
At the top of your .y file, you’ll need to include your AST class headers and use std::shared_ptr.
%{
#include "ASTNodes.hpp"
#include <memory>
using namespace std;
%}
Also, define the type of YYSTYPE, so Bison knows what value each rule returns.
%union {
int intVal;
char* strVal;
shared_ptr<ASTNode> node;
shared_ptr<ExprNode> expr;
shared_ptr<StmtNode> stmt;
vector<shared_ptr<ASTNode>>* nodeList;
}
You can expand this union with specific pointer types for various node categories (like ExprNode, StmtNode, etc.) for better type safety.
Step 2: Declare Token and Nonterminal Types
Next, declare types for each terminal and non-terminal symbol.
%token <strVal> IDENTIFIER
%token <intVal> INTEGER
%type <expr> expr term factor
%type <stmt> statement
%type <nodeList> block
This tells Bison what kind of data each rule returns — a number, a string, a node pointer, or a vector of nodes.
Step 3: Modify Grammar Rules to Build AST Nodes
This is the real magic.
Let’s take a simple arithmetic grammar and show how to modify each rule to create AST nodes on the fly:
expr:
expr '+' term {
$$ = make_shared<BinaryExprNode>("+", $1, $3);
}
| expr '-' term {
$$ = make_shared<BinaryExprNode>("-", $1, $3);
}
| term {
$$ = $1;
};
term:
term '*' factor {
$$ = make_shared<BinaryExprNode>("*", $1, $3);
}
| term '/' factor {
$$ = make_shared<BinaryExprNode>("/", $1, $3);
}
| factor {
$$ = $1;
};
factor:
INTEGER {
$$ = make_shared<IntLiteralNode>($1);
}
| IDENTIFIER {
$$ = make_shared<VariableNode>(string($1));
}
| '(' expr ')' {
$$ = $2; // Parentheses just pass through the inner expression
};
Let’s break that down:
Rule | What It Builds |
expr ‘+’ term | A BinaryExprNode for addition |
term ‘*’ factor | A BinaryExprNode for multiplication |
INTEGER | An IntLiteralNode storing the number |
IDENTIFIER | A VariableNode representing a variable name |
Why use make_shared?
It creates shared_ptr instances in a clean, efficient way — avoiding raw pointers and memory leaks.
How AST Is Built Recursively
Bison builds the AST bottom-up, which works beautifully with recursive grammar.
For a + b * c, Bison processes:
- b * c → creates BinaryExprNode(“*”, b, c)
- Then, a + (b * c) → creates BinaryExprNode(“+”, a, (* b c))
At each stage, you’re combining smaller subtrees into a bigger one.
Common Pitfalls (And How to Avoid Them)
Problem | Cause | Fix |
Segmentation Faults | Using raw pointers or not assigning $$ | Use shared_ptr + always assign $$ |
Incorrect tree structure | Incorrect grammar precedence or missing parentheses handling | Use %left, %right declarations to manage precedence |
Uninitialized tokens | Using $1 for tokens without declared types | Make sure tokens like INTEGER have <intVal> in %token |
Incorrect memory handling | Using new without delete or mixing with smart pointers | Always prefer make_shared<T>(…) |
Step 4: Define Precedence and Associativity (Optional but Useful)
If you want to handle precedence cleanly and avoid left-recursion ambiguity, declare operator precedence at the top:
%left '+' '-'
%left '*' '/'
This helps Bison resolve ambiguous parses automatically — e.g., that * binds tighter than +.
Step 5: Return AST from program Rule
At the top level, your grammar should return the full AST for the entire program. For example:
program:
block {
$$ = make_shared<ProgramNode>(*($1));
delete $1; // Clean up heap-allocated vector
};
Now, your main() can call yyparse() and get the root of your AST.
Step 6: Generate Parser with Bison and Integrate into Build
To generate the parser and header files:
bison -d flare.yThis produces:
- flare.tab.cpp → Parser implementation
- flare.tab.hpp → Token and AST declarations
Then, compile and link with your project:
g++ -o flare compiler_main.cpp lexer.cpp flare.tab.cpp ASTNodes.cpp -std=c++17Your lexer (lexer.cpp) should provide tokens to Bison, and your parser (yyparse()) will now build a fully functional AST!
Organizing AST Code
As the AST grows, it’s important to organize things cleanly.
Suggested File Structure:
/src
├── ASTNodes.hpp // AST class declarations
├── ASTNodes.cpp // AST class definitions
├── flare.y // Bison grammar file
└── ...
C++ Best Practices:
- Use shared_ptr<ASTNode> everywhere to avoid manual memory management.
- Create helper functions if node creation gets repetitive.
- Use polymorphism (virtual methods) for future extensions like printing, evaluating, or code generation.
Visualizing and Debugging the AST
A good AST is useless if you can’t see it.
Implement a print() method in each node to print the tree:
// In BinaryExprNode
void print() override {
cout << "(" << op << " ";
left->print();
cout << " ";
right->print();
cout << ")";
}
This can help you debug and verify if your grammar rules and AST structures match the code’s meaning.
Summary
- We defined an AST using C++ classes.
- Then, we updated the Bison grammar rules to build that AST directly using $$ = make_shared<…>().
- We declared types for tokens and non-terminals using %union and %type.
- We ensured proper memory management using shared_ptr.
- We tied everything together by returning the full AST from the top rule.
At this point, you’ve built a fully working AST generator that constructs the backbone of your source code’s structure. Your parser no longer just checks syntax — it produces a rich tree representation that captures the meaning of code written in your language.
But we’re not done yet. In fact, we’re now standing at the most intellectually exciting point in our compiler journey — semantic analysis.
