Intro
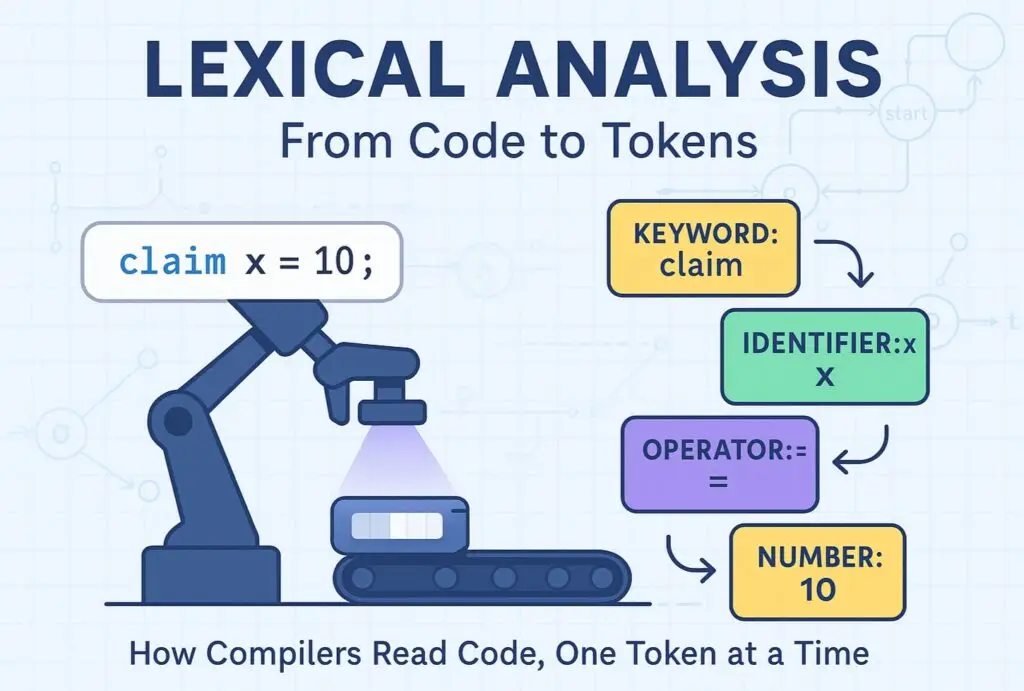
Before a compiler can understand what you mean by claim x = 10;, it has to break the code into meaningful pieces—just like how our brain splits a sentence into words and punctuation. This first phase of compilation, called lexical analysis, is done by the lexer (a.k.a. tokenizer). Without it, all your carefully written syntax remains a stream of meaningless characters.
In this post, we’ll delve into the depths of lexers, exploring what they are, why they’re essential, and how they work under the hood. You’ll learn advanced concepts—from finite automata and state machines to performance tuning—and see how to implement a robust, efficient lexer for Flare in C++ using regular expressions and manual scanning.
In Part 1, we designed Flare, a dynamic, block-scoped programming language. We made key decisions on typing, syntax, scoping, and core features. Now, it’s time to implement the first compiler stage: lexing.
What Is a Lexical Analysis?
A lexer (also called a lexical analyzer or tokenizer) is the first formal phase of a compiler. It takes your raw source code — a continuous stream of characters — and partitions it into tokens, the fundamental building blocks that represent meaningful language elements. But a production-quality lexer does much more than simple splitting; it employs formal language theory, performance optimizations, and error-handling strategies.
➤ The What: Tokens, Lexemes, and Categories
- Lexemes are the exact character sequences consumed (e.g., claim, x, 42, “hello”). Think of them as the raw words in a sentence before labeling their parts of speech.
- Tokens are structured representations of lexemes: they include a type (e.g., KEYWORD, IDENTIFIER, INT_LITERAL), the lexeme itself, and metadata like line and column numbers. In natural language processing, tokens would be words tagged with their grammatical role.
- Categories group tokens by their role:
- Keywords: Reserved words the language defines (claim, create, drop).
- Identifiers: Names defined by the user (variables, functions, types).
- Literals: Numeric (42, 3.14) or string (“Flare”).
- Operators: Symbols representing operations (+, ==, >>).
- Delimiters/Punctuators: Characters that separate or group tokens (;, ,, {, }).
- Comments/Whitespace: Ignored lexemes, but important for readability and error reporting.
Analogy: Like reading a sentence, you first split on spaces and punctuation (lexemes), then tag each word as noun, verb, adjective (tokens) before parsing the sentence structure.
➤ The Why: Purpose and Benefits of Lexer
- Simplify the Parser’s Job
Parsers operate on a stream of tokens, not raw text. By cleaning up whitespace and comments, the lexer delivers a concise token sequence so the parser can focus on grammar rules. - Early Error Detection
Malformed numbers (123abc), unterminated strings, or illegal characters (@) can be caught immediately. This provides clear, early feedback to the programmer. - Performance and Scalability
High-quality lexers use techniques like fast DFA-based scanning and buffered I/O to process millions of lines per second. This is critical in large codebases or IDEs that require real-time syntax highlighting. - Modular Compiler Architecture
By decoupling lexing from parsing, each stage can be developed, optimized, and tested independently. This separation of concerns leads to cleaner, more maintainable compiler code.
➤ The How: Core Algorithms and Data Structures
- Deterministic Finite Automaton (DFA)
- A DFA is a state machine where each state represents part of a tokenization context (e.g., default, number, identifier). Regular expressions for each token type are compiled into state-transition tables, allowing the lexer to scan in O(n) time relative to input length.
- Example: To recognize an identifier, the DFA starts in a state that accepts letters/underscores, stays in that state as long as the input matches letters/digits/underscores, then transitions to an accept state when the next character is non-matching.
- Longest-Match (Maximal Munch) Rule
- When multiple token patterns match the input, the lexer chooses the longest valid lexeme. For instance, given !=, it should match the two-character != operator, not ! followed by =.
- Lookahead Buffer
- Lexers often need to peek ahead one or more characters without consuming them, to decide if a multi-character operator or number literal continues. A small lookahead buffer (1–2 chars) handles cases like ==, <=, and >>.
- Two-Buffer Technique
- To minimize expensive file I/O, input is divided into two alternating buffers. When one buffer is exhausted, the lexer switches to the other and reloads data seamlessly. This technique avoids copying data and handles tokens spanning buffer boundaries.
- Position Tracking
- The lexer maintains line and column counters, incrementing them on or any consumed character. This data is attached to each Token for precise error messages and IDE features like “go to error.”
Example: Reading a multiline string, the lexer tracks line breaks so if the string isn’t closed, it can report: “Unterminated string at line 12, column 8.”
➤ Advanced Topics You Can Explore
- Unicode and UTF-8 Support: Handling multi-byte characters in identifiers and string literals.
- Error Recovery: Strategies like panic mode (skip tokens until a safe point) and token insertion/deletion for resilient parsing.
- Performance Optimizations: Compare table-driven DFAs vs. handcrafted switch-case lexers, and branchless scanning techniques.
- Mode-Switching Lexers: For languages with embedded syntax (e.g., regex, HTML), lexers can switch contexts dynamically.
Regex in Lexer Construction
What is Regex?
Regular Expressions (regex) are symbolic patterns used to match strings. Think of them as mini-languages for describing the shape and structure of text. At a high level, regex provides a way to:
- Identify strings that match a pattern (like “abc”, digits, identifiers).
- Extract matched components (e.g., capturing numbers or quoted strings).
- Validate whether a sequence of characters fits a grammar rule.
Example Regex Patterns:
|
Pattern |
Matches |
|
[a-zA-Z_]\w* |
Identifiers like x, sum1, is_valid |
|
\d+ |
Integer literals like 42, 1000 |
|
`”(?:\. |
[^”\])*”` |
|
`== |
!= |
|
\s+ |
Whitespace (used to ignore or skip) |
How Is Regex Used in Lexical Analysis?
In lexers, regex defines the language’s vocabulary. Each type of token (identifier, number, keyword, etc.) is described using a regex pattern. The lexer scans the source code using these patterns, matches the longest valid token at each step, and converts the raw code into a sequence of tokens.
This process can be manual (code uses regex directly) or automated using tools like Flex, re2c, or hand-coded DFAs that are generated from regex definitions.
Here’s how regex powers each stage:
- Lexeme Detection: The lexer checks which regex pattern matches the current input.
- Token Categorization: Once matched, the lexer tags the lexeme with the corresponding token type (e.g., TokenType::Identifier).
- Lexeme Validation: Malformed strings, unclosed quotes, or illegal characters are caught early.
- Efficiency: Regex-based DFAs allow scanning in linear time (O(n)), critical for performance.
Regex Tokenization Algorithm (Step-by-Step)
Let’s walk through how a regex-based lexer works using pseudocode:
Step 1: Define Token Patterns
C++
vector<pair<string, regex>> compiledRegexes = {
{"int_L", regex(R"([0-9]+)")},
{"frac_L", regex(R"([0-9]+\.[0-9]*)")},
{"text_L", regex(R"("(?:(?:\\.)|[^"])*")")},
{"comment", regex(R"(#(.*?)#)")},
{"arth_op", regex(R"(\*\*|//|\+|\-|\*|/|%)")},
{"cond_op", regex(R"(<=|>=|==|!=|<|>)")},
{"assgn_op", regex(R"(=)")},
{"mod_ind", regex(R"(>>)")},
{"paren", regex(R"([\(\)\[\]\{\}])")},
{"ws", regex(R"([\t]+)")},
{"nl", regex(R"(\r?\n)")},
{"spec_char",regex(R"(:|,|;|\.)")},
{"quote", regex(R"(")")},
{"Keyword", regex(R"(int|frac|flag|letter|text|Null|list|dict|tuple|True|False|claim|check|altcheck|alt|during|loop|over|span|create|drop|and|or|not|skip|stop)")},
{"inbuilt_fn", regex(R"(display|read|to_int|to_frac|to_flag|to_letter|to_text|typeof|length|contain|insert|remove|erase|clear)")},
{"Identifier", regex(R"([a-zA-Z][a-zA-Z0-9_]*)")}
};
Step 2: Tokenization Logic
C++ Implementation:
int yylex() {
while (pos < inputCode.length()) {
string bestToken = "";
string bestType = "";
size_t bestSize = 0;
smatch match;
string remaining = inputCode.substr(pos);
for (const auto& pair : compiledRegexes) {
if (regex_search(remaining, match, pair.second) && match.position() == 0) {
size_t tokenSize = match.length();
if (tokenSize > bestSize) {
bestToken = match.str();
bestType = pair.first;
bestSize = tokenSize;
}
}
}
if (bestSize == 0) {
pos++; // Skip unknown character
continue;
}
pos += bestSize; // Move forward
// Ignore whitespace and comments
if (bestType == "nl") {
yylineno++; // Track line numbers
continue;
}
if (bestType == "ws" || bestType == "comment")
continue;
// Convert to specific token types using a helper function
yytext = bestToken;
// cout << bestToken << "\t \t " << bestType << "\t \t " << yylineno << endl;
return getTokenType(bestToken, bestType);
}
return 0; // End of input
}
Why is the function called yylex()?
If you’ve never worked with lexers or parser generators like Lex/Flex, this name might seem strange. Here’s why it exists:
- yylex is a conventional function name used by tools like Flex to represent the lexer’s main function.
- The parser calls yylex() to get the next token. This function returns an integer token code (e.g., TOK_IDENTIFIER, TOK_NUMBER) that the parser uses to drive parsing.
- Even when writing a manual lexer, using the name yylex() ensures compatibility with Bison or any hand-written parser expecting this naming convention.
You can rename it (e.g., to nextToken()), but if you plan to integrate with tools like Bison later, sticking with yylex() is a good idea.
What does yylex() actually do?
This function reads the input source code (stored in inputCode) from a global pos index and tokenizes it using a set of precompiled regex patterns, stored in compiledRegexes.
Let’s go through it line-by-line:
Full Breakdown
int yylex() {
while (pos < inputCode.length()) {
- A loop runs while there’s still code left to process.
- pos is the current position in the source string.
string bestToken = "";
string bestType = "";
size_t bestSize = 0;
smatch match;
string remaining = inputCode.substr(pos);
- bestToken: Stores the matched lexeme.
- bestType: Stores the type (e.g., “identifier”, “number”).
- bestSize: Used to apply the Longest Match Rule — we always want the longest valid token at each step.
- match: A container for storing regex match results.
- remaining: The substring of code we haven’t scanned yet.
for (const auto& pair : compiledRegexes) {
if (regex_search(remaining, match, pair.second) && match.position() == 0) {
This loop checks all token patterns:
- compiledRegexes is a map: token type → compiled regex pattern.
- regex_search(…) checks if the pattern matches from the beginning.
- The match.position() == 0 condition ensures we’re not matching things in the middle—we only want matches at the current pos.
size_t tokenSize = match.length();
if (tokenSize > bestSize) {
bestToken = match.str();
bestType = pair.first;
bestSize = tokenSize;
}
- If this pattern matched longer than the previous best match, we update our best match info.
- This enforces the “longest match wins” strategy (e.g., choose == over =).
if (bestSize == 0) {
pos++; // Skip unknown character
continue;
} pos += bestSize; // Move forward
- If no regex matched, we assume the character is illegal or unrecognized.
- We skip it (and might want to log an error or warning later).
- Once a match is accepted, move the cursor forward in the input.
// Ignore whitespace and comments
if (bestType == "nl") {
yylineno++; // Track line numbers
continue;
}
if (bestType == "ws" || bestType == "comment")
continue;
- Skip tokens we don’t care about, like whitespace (“ws”) or comments.
- “nl” tracks newlines so we can update yylineno for accurate error reporting later in parsing.
// Convert to specific token types using a helper function
yytext = bestToken;
return getTokenType(bestToken, bestType);
}
return 0; // End of input
}
- The matched token is stored in yytext (another Flex/Bison convention).
- getTokenType() is a helper that converts the type + lexeme into a specific token code.
- Returning 0 signifies end-of-file (EOF) to the parser.
This is the longest-match-first, priority-ordered matching loop, where the lexer tries each pattern in order and consumes the matched portion of text once successful.
Example: Lexing This Input
Flare :
claim x = 42;
Output Tokens:
[
{ "type": "Keyword", "value": "claim" },
{ "type": "Identifier", "value": "x" },
{ "type": "assgn_op", "value": "=" }, { "type": "int_L", "value": "42" }, { "type": "spec_char", "value": ";" }, ]
Next Steps in the Compiler Pipeline
Once the lexer produces a list of tokens, the parser takes over—transforming these tokens into a syntax tree that represents the program’s structure.
From here, we move into:
- Parser Design: Defining the grammar using BNF and constructing ASTs.
- AST Construction: Building tree structures from token streams.
- Semantic Analysis: Validating scopes, types, and control flow.
- Code Generation: Emitting machine code or LLVM IR.